Code Request
Filling out this form will grant you access to all of the code on this site. In addition, you will join our mailing list, and we'll send you periodic updates regarding new articles.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
June 21, 2023
Python Lead Generation: Scraping Businesses on yellowpages.com
Scraping the Yellow Pages to Extract Business Contact Info
Click here to download this post's source code
How can you use Python to web scrape business contact info, including emails and businesses? In this article, we'll scrape yellowpages.com for emails, phone numbers, and addresses.

Photo by Mike Meyers on Unsplash
Introduction
Generating leads can be a difficult process, and many web scraping solutions cost money; how can we gather the contact information of businesses for free?
Some websites make this task easy for us. For example, yellowpages.com, a digital version of the physical books, provides categories of businesses with their addresses, emails, and phone numbers. The best part: the site is incredibly easy to scrape, and, with some code setup, you can extract this data by yourself!
Setup
The Python code accompanying this article can be downloaded here.
To get started, there are several libraries that you need to install:
pip install requests
pip install bs4
If you aren't already familiar, the requests library allows us to connect to the website, and the bs4 library can be used for parsing HTML.
Understanding yellowpages.com

yellowpages.com can be searched via a string query, including keywords, and location. A typical URL looks something like this:
Say I want to search for pizza places in New York, the URL would look something like this:
Here's a sample of the results:
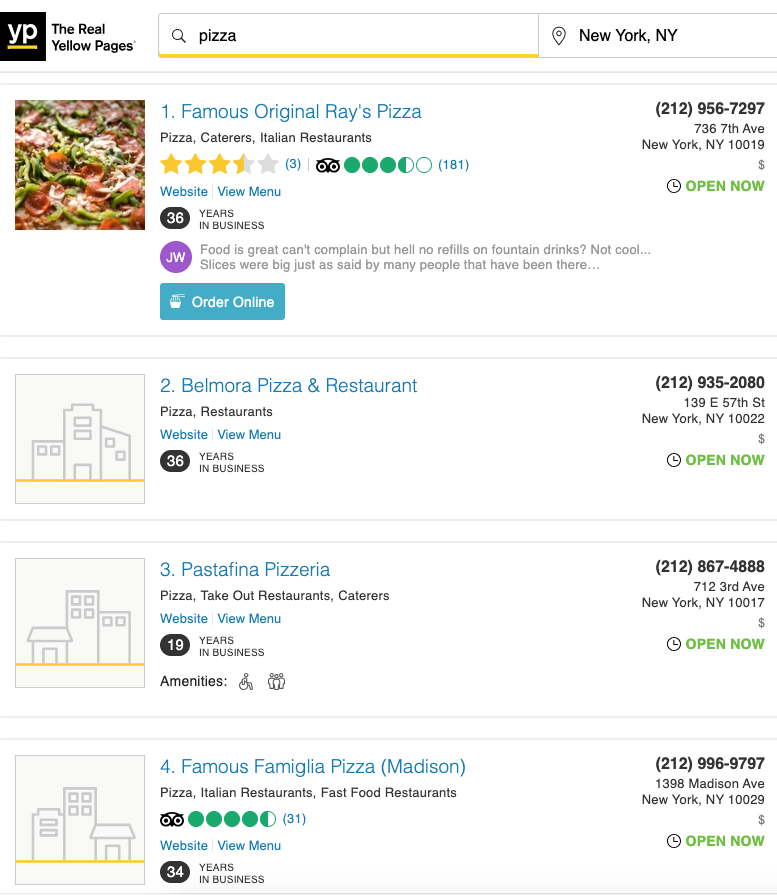
This is a sample of the 1755 results we can scrape from this single query!
Each result leads to a different business listing, something like this one: https://www.yellowpages.com/new-york-ny/mip/famous-original-rays-pizza-459218516 .
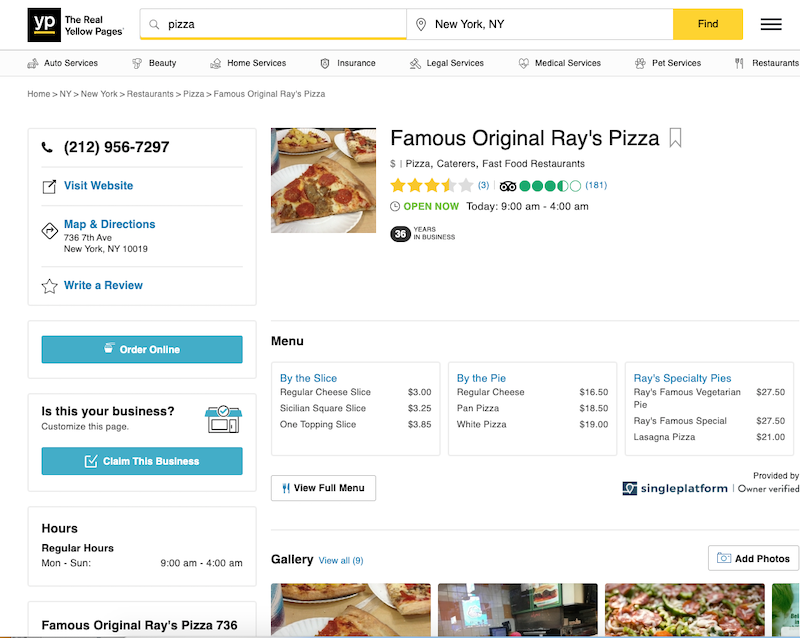
hello world
Extracting the Search Results
To get started, open a new file named yellowpages-urls.py (or open the downloadable version) and import the necessary libraries:
import requests
from bs4 import BeautifulSoup
def str_to_url_value(string):
return string.replace(' ', ' ').replace(',', ',')
def get_search_url(query, location):
search_url_format = 'https://www.yellowpages.com/search?search_terms={}&geo_location_terms={}'
search_url = search_url_format.format(query.replace(' ', '+').replace(',', ','), location.replace(' ', '+').replace(',', ','))
return search_url
search_query = 'Pizza'
search_location = 'New York'
search_url = get_search_url(search_query, search_location)
html = requests.get(search_url).text
print(html)
The above code formats the URL like we talked about, taking in the search query and location data as input, and requesting the webpage from the yellowpages.com server. If the code is working, the result should look something like this:
<!DOCTYPE html><html lang="en"><head><script>(function(...
Now, let's get the URLs results on this page. For that, we'll need to use an HTML parser, provided by the BeautifulSoup (bs4) library:
soup = BeautifulSoup(html, features='html.parser')
all_results = soup.find_all('a', {'class': 'business-name'})
all_results_hrefs = ['https://www.yellowpages.com' + x['href'] for x in all_results]
print(all_results_hrefs)
Each search result has an <a href> listing with the class business-name. We used BeautifulSoup to find all of the a tags with that class. The result:
['https://www.yellowpages.com/new-york-ny/mip/famous-original-rays-pizza-459218516', 'https://www.yellowpages.com/new-york-ny/mip/rockefeller-center-455621388', 'https://www.yellowpages.com/new-york-ny/mip/olio-e-pi-458022662', 'https://www.yellowpages.com/new-york-ny/mip/capizzi-456812096', ...]
You can get all of the results (on all of the available pages) by iterating the page value in the yellowpages search URL. You can find the code for that in the iterate-pages.py file in the source code.
Scraping a Business Page
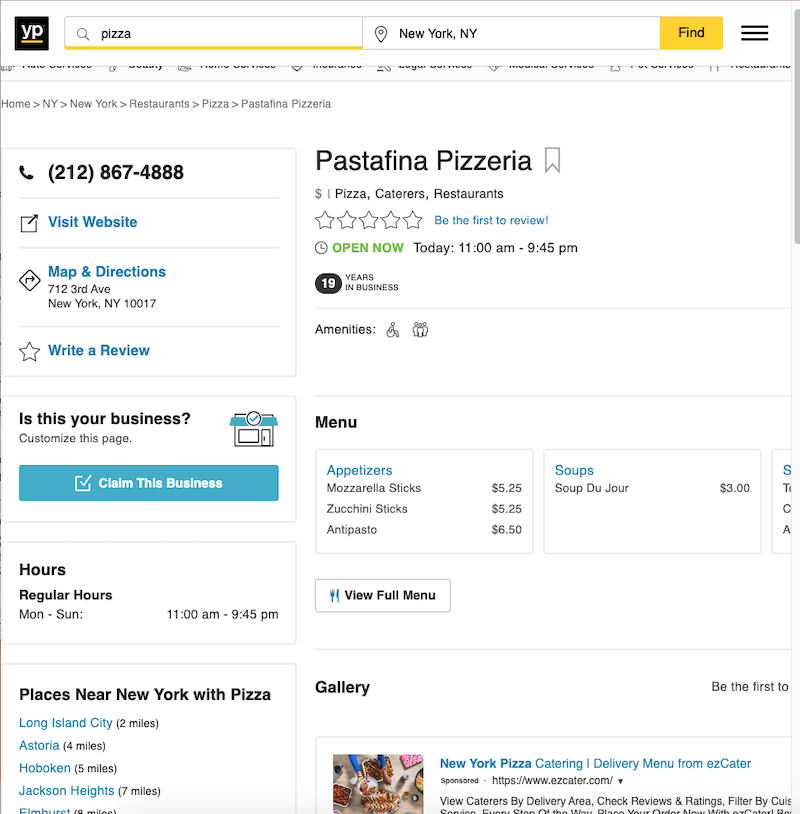
Now that we can get the business search results, let's try scraping one of them:
import requests
from bs4 import BeautifulSoup
url_result = 'https://www.yellowpages.com/new-york-ny/mip/pastafina-pizzeria-3043273'
html = requests.get(url_result).text
If we try to get the attributes of an element which can't be found (such as element.text, element['href']), we'll get an error; to circumvent this, we need a function to extract the attribute from the element if it exists, and to otherwise returl some default value:
def get_val_from_elem(soup, item_type, item_attr, get_href=False):
element = soup.find(item_type, item_attr)
if element:
if get_href:
return element['href']
else:
return element.text
else:
return ''
The above function takes in the soup, the item type (tag name) and item selector ({'class': 'business-name'}).
The class for business names is aptly "business_name", as you can tell if you inspect the HTML. Here's how our new function can be used to get that value:
soup = BeautifulSoup(html, features='html.parser')
business_name = get_val_from_elem(soup, 'h1', {'class': 'business-name'})
print(business_name)
# Pastafina Pizzeria
In a similar manner, we can get the business email, phone number, and address.
Business Email:
business_email = get_val_from_elem(soup, 'a', {'class': 'email-business'}, get_href=True).replace('mailto:', '')
print(business_email)
# [email protected]
Phone Number:
phone_number = get_val_from_elem(soup, 'a', {'class': 'phone'})
print(phone_number)
# (212) 867-4888
Address is more complicated, as it often includes a span tag, and just getting the text will remove implied newlines. We need get the text from each child of the element and join them together with newlines. We can do that like so:
address_elem = soup.find('span', {'class': 'address'})
address_text = '
'.join([x.text for x in address_elem.children])
print(address_text)
# 712 3rd Ave
# New York, NY 10017
A bot that can automate the process described in this article can be found in the iterate-pages.py file.